[작성일: 2023. 10. 03]
컬렉션 조회 최적화(1)
주문 조회 V1: 엔티티 직접 노출
주문내역에서 추가로 주문한 상품 정보를 추가로 조회하려면 Order 기준으로 컬렉션인 OrderItem과 Item이 필요하다.
지금은 OneToOne, ManyToOne 관계만 있다.
이번에는 컬렉션인 일대다 관계(OneToMany)를 조회하고 최적화 하는 방법을 알아보자.
@RestController
@RequiredArgsConstructor
public class OrderApiController {
private final OrderRepository orderRepository;
@GetMapping("/api/v1/orders")
public List<Order> ordersV1() {
List<Order> all = orderRepository.findAllByString(new OrderSearch());
for (Order order : all) {
order.getMember().getName();
order.getDelivery().getAddress();
List<OrderItem> orderItems = order.getOrderItems();
orderItems.stream().forEach(
o -> o.getItem().getName());
}
return all;
}
}

orderItem, Item 관계를 직접 초기화하면 Hibernate5JakartaModule 설정에 의해 엔티티를 JSON으로 생성한다.
양방향 연관관계면 무한 루프에 걸리지 않게 한 곳에 @JsonIgnore를 추가해야 한다.
하지만 엔티티를 직접 노출하는 것은 좋은 방법이 아니다.
주문 조회 V2: 엔티티를 DTO로 변환
@RestController
@RequiredArgsConstructor
public class OrderApiController {
private final OrderRepository orderRepository;
// ... 코드 생략
@GetMapping("/api/v2/orders")
public List<OrderDto> ordersV2() {
List<Order> orders = orderRepository.findAllByString(new OrderSearch());
List<OrderDto> collect = orders.stream().map(o -> new OrderDto(o))
.collect(Collectors.toList());
return collect;
}
@Data
static class OrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItemDto> orderItems;
public OrderDto(Order order) {
orderId = order.getId();
name = order.getMember().getName();
orderDate = order.getOrderDate();
orderStatus = order.getStatus();
address = order.getDelivery().getAddress();
orderItems = order.getOrderItems().stream()
.map(orderItem -> new OrderItemDto(orderItem))
.collect(Collectors.toList());
}
}
@Data
static class OrderItemDto {
private String itemNames;
private int orderPrice;
private int count;
public OrderItemDto(OrderItem orderItem) {
itemNames = orderItem.getItem().getName();
orderPrice = orderItem.getOrderPrice();
count = orderItem.getCount();
}
}
}

지연 로딩으로 인해 너무 많은 SQL이 실행되고 있다.
- order 1번
- member, address N번(order 조회 수만큼)
- orderItem N번(order 조회 수만큼)
- item N번(orderItem 조회 수만큼)
참고: 지연 로딩연 영속성 컨텍스트에 있으면 영속성 컨텍스트에 있는 엔티티를 사용하고, 없으면 SQL을 실행한다.
따라서 같은 영속성 컨텍스트에서 이미 로딩한 회원 엔티티를 추가로 조회하면 SQL을 실행하지 않는다.
주문 조회 V3: 엔티티를 DTO로 변환 - 페치 조인 최적화
@RestController
@RequiredArgsConstructor
public class OrderApiController {
private final OrderRepository orderRepository;
// ... 코드생략
@GetMapping("/api/v3/orders")
public List<OrderDto> ordersV3() {
List<Order> orders = orderRepository.findAllWithItem();
List<OrderDto> collect = orders.stream().map(o -> new OrderDto(o))
.collect(Collectors.toList());
return collect;
}
@Data
static class OrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItemDto> orderItems;
public OrderDto(Order order) {
orderId = order.getId();
name = order.getMember().getName();
orderDate = order.getOrderDate();
orderStatus = order.getStatus();
address = order.getDelivery().getAddress();
orderItems = order.getOrderItems().stream()
.map(orderItem -> new OrderItemDto(orderItem))
.collect(Collectors.toList());
}
}
@Data
static class OrderItemDto {
private String itemNames;
private int orderPrice;
private int count;
public OrderItemDto(OrderItem orderItem) {
itemNames = orderItem.getItem().getName();
orderPrice = orderItem.getOrderPrice();
count = orderItem.getCount();
}
}
}
@Repository
@RequiredArgsConstructor
public class OrderRepository {
private final EntityManager em;
// ... 코드생략
public List<Order> findAllWithItem() {
return em.createQuery(
"select distinct o from Order o " +
" join fetch o.member m" +
" join fetch o.delivery d" +
" join fetch o.orderItems oi" +
" join fetch oi.item i", Order.class)
.getResultList();
}
}
페치 조인으로 SQL이 한 번만 실행된다.
distinct를 사용한 이유는 일대다 조인이 있으므로 데이터베이스 row가 증가한다. 그 결과 같은 order 엔티티의 조회 수도 증가하게 된다.
JPA의 distinct는 SQL에 distinct를 추가하고, 같은 엔티티가 조회되면 애플리케이션에서 중복을 걸러준다.
참고:
컬렉션 페치 조인을 사용하면 페이징이 불가능하다. 하이버네이트는 경고 로그를 남기면서 모든 데이터를 DB에서 읽어오고 메모리에서 페이징 해버린다.(매우 위험!)
컬렉션 페치 조인은 1개만 사용할 수 있다. 데이터가 부정합하게 조회될 수 있으므로 컬렉션 둘 이상에 페치 조인을 사용하면 안 된다.
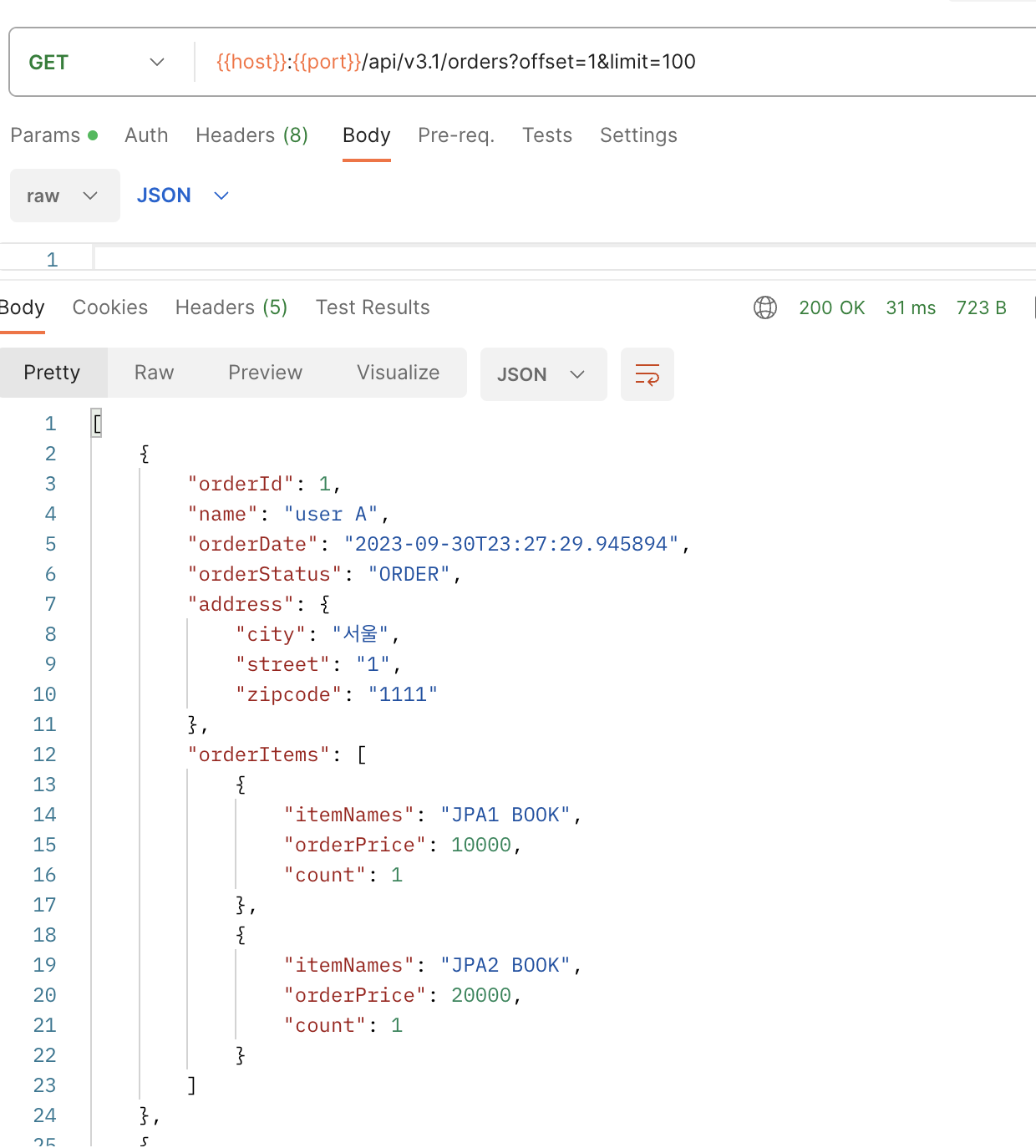
주문 조회 V3.1: 엔티티를 DTO로 변환 - 페이징과 한계 돌파
컬렉션을 페치 조인하면 일대다 조인이 발생하므로 데이터가 예측할 수 없이 증가한다.
일대다에서 일(1)을 기준으로 페이징을 하는 것이 목적인데 데이터는 다(N)을 기준으로 row가 생성된다.
Order를 기준으로 페이징 하고 싶은데, 다(N)인 OrderItem을 조인하면 OrderItem이 기준이 되어버리는 것이다.
이 경우 하이버네이트는 경고 로그를 남기고 모든 DB 데이터를 읽어서 메모리에서 페이징을 시도하며, 최악의 경우 장애가 발생한다.
그러면 페이징 + 컬렉션 엔티티를 함께 조회하려면 어떻게 해야할까?
- 먼저 ToOne(OneToOne, ManyToOne) 관계를 모두 페치 조인한다. ToOne 관계는 row 수를 증가시키지 않으므로 페이징 쿼리에 영향을 주지 않는다.
- 컬렉션은 지연 로딩(LAZY)으로 조회한다.
- 지연 로딩 성능 최적화를 위해 hibernate.default_batch_fetch_size, @BatchSize를 적용한다.
- hibernate.default_batch_fetch_size: 글로벌 설정
- @BatchSize: 개별 최적화
- 이 옵션을 사용하면 컬렉션이나 프록시 객체를 한꺼번에 설정한 size 만큼 IN 쿼리로 조회한다.
@RestController
@RequiredArgsConstructor
public class OrderApiController {
private final OrderRepository orderRepository;
// ... 코드생략
@GetMapping("/api/v3.1/orders")
public List<OrderDto> ordersV3_page(@RequestParam(value = "offset", defaultValue = "0") int offset,
@RequestParam(value = "limit", defaultValue = "100") int limit) {
List<Order> orders = orderRepository.findAllWithMemberDelivery();
List<OrderDto> collect = orders.stream().map(o -> new OrderDto(o))
.collect(Collectors.toList());
return collect;
}
@Data
static class OrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItemDto> orderItems;
public OrderDto(Order order) {
orderId = order.getId();
name = order.getMember().getName();
orderDate = order.getOrderDate();
orderStatus = order.getStatus();
address = order.getDelivery().getAddress();
orderItems = order.getOrderItems().stream()
.map(orderItem -> new OrderItemDto(orderItem))
.collect(Collectors.toList());
}
}
@Data
static class OrderItemDto {
private String itemNames;
private int orderPrice;
private int count;
public OrderItemDto(OrderItem orderItem) {
itemNames = orderItem.getItem().getName();
orderPrice = orderItem.getOrderPrice();
count = orderItem.getCount();
}
}
}
@Repository
@RequiredArgsConstructor
public class OrderRepository {
private final EntityManager em;
// ... 코드생략
public List<Order> findAllWithMemberDelivery(int offset, int limit) {
return em.createQuery(
"select o from Order o " +
" join fetch o.member m" +
" join fetch o.delivery d", Order.class)
.setFirstResult(offset)
.setMaxResults(limit)
.getResultList();
}
}
jpa:
hibernate:
ddl-auto: create
properties:
hibernate:
# show_sql: true
format_sql: true
default_batch_fetch_size: 100
application.yml에 default_batch_fetch_size: 100을 추가한다. (in 쿼리의 개수)
개별로 설정하려면 @BatchSize를 적용하면 된다. 컬렉션은 컬렉션 필드에, 엔티티는 엔티티 클래스에 적용하면 된다.
- 쿼리 호출 수가 1+N에서 1+1로 최적화 된다.
- 조인보다 DB 데이터 전송략이 최적화 된다.
- Order와 OrderItem을 조인하면 Order가 OrderItem만큼 중복해서 조회된다.
- 이 방법은 각각 조회하므로 전송해야 할 중복 데이터가 없다.
- 페치 조인 방식과 비교해서 쿼리 호출 수가 약간 증가하지만 DB 데이터 전송량이 감소한다.
- 컬렉션 패치 조인은 페이징이 불가능하지만 이 방법은 페이징이 가능하다.
- ToOne 관계는 페치 조인을 해도 페이징에 영향을 주지 않는다. 따라서 ToOne 관계는 페치 조인으로 쿼리 수를 줄이고, 나머지는 hibernate.default_batch_fetch_size로 최적화 하면 된다.
참고:
default_batch_fetch_size의 크기는 적당한 사이즈를 골라야 하는데 100 ~ 1000 사이를 선택하길 권장한다.
이 전략을 SQL IN 절을 사용하는데 데이터베이스에 따라 IN절 파라미터를 1000으로 제한하기도 한다.
1000으로 잡으면 한 번에 1000개를 DB에서 애플리케이션에 불러오므로 순간 DB에 부하가 증가할 수 있다. 하지만 애플리케이션은 100이든 1000이든 결국 전체 데이터를 로딩해야 하므로 메모리 사용량은 같다.
1000으로 설정하는 것은 성능 상 가장 좋지만, 결국 DB든 애플리케이션이든 순간 부하를 어디까지 견딜 수 있는지로 결정하면 된다.
참고: 스프링부트 3.1부터는 하이버네이트 6.2를 사용하는데 where in 대신에 array_contains를 사용한다.
where in 사용 문법은 where item.item_id in(?,?,?,?)
array_contains 사용 문법은 where array_contains(?, item.item_id)
where in에서 array_contains를 사용하도록 변경해도 결과는 완전 동일하지만 변경하는 이유는 성능 최적화 때문이다.
array_contains에서 default_batch_fetch_size에 맞추어 배열에 null값을 추가하는데 특정 데이터베이스에 따라 배열의 데이터 숫자가 같아야 최적화 되기 때문에 그런 것으로 추정된다고 한다.
🐣 출처: 인프런 김영한님 강의
이 글은 인프런의 김영한님 JPA 강의를 보고 작성한 글입니다.
강의를 들으면서 정리한 글이므로 틀린 내용이나 오타가 있을 수 있습니다.